Autoencoders
Autoencoders são redes neurais que tem sido usadas para redução de ruído em imagens (denoising) e também para redução de dimensionalidade. Eles são redes neurais em que a saída é uma estimativa da própria entrada. Eles comprimem a entrada em um código de menor dimensão e, em seguida, reconstroem a saída a partir dessa representação. O código gerado também é chamado de representação do espaço latente.
Um autoencoder é composto por três componentes: codificador, código e decodificador, como mostrado na Figura 1. O codificador comprime a entrada e produz o código, o decodificador então reconstrói a entrada usando apenas esse código.
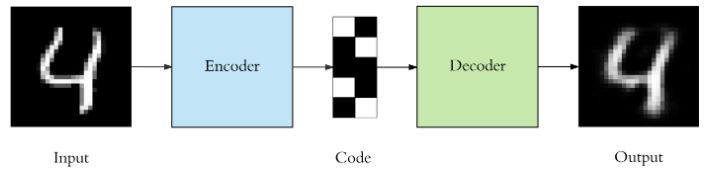
Para construir um autoencoder, precisamos de um método de codificação, um método de decodificação e uma função de perda para comparar a saída com a entrada. Autoencoders são usados principalmente para redução de dimensionalidade (ou compressão) com algumas propriedades importantes:
- Dados específicos: Autoencoders só são capazes de compactar significativamente dados semelhantes aos que foram treinados. Eles aprendem recursos específicos para os dados de treinamento fornecidos. Portanto, não podemos esperar que um autoencoder treinado em dígitos manuscritos comprima fotos de paisagens.
- Com perdas: A saída do autoencoder não será exatamente igual à entrada, será uma representação próxima, mas degradada. Se você deseja compactação sem perdas, essa não é a melhor solução.
- Não supervisionado: Para treinar um autoencoder, precisamos apenas lançar os dados brutos de entrada nele. Alguns autores interpretam autoencoders como uma técnica de aprendizagem não supervisionada, uma vez que eles não precisam de rótulos explícitos para treinar. No entanto, o mais correto é dizer que sua aprendizagem é auto supervisionada porque eles geram seus próprios rótulos a partir dos dados de treinamento.
Arquitetura
Tanto o codificador quanto o decodificador são redes neurais totalmente conectadas, como uma MLP ou CNN. O código é uma única camada cujo número de neurônios no caso de uma MLP ou de filtros no caso de uma CNN deve ser escolhido. Esse número também chamado de tamanho do código é um hiperparâmetro que deve ser definido antes de treinar o autoencoder. Na Figura 2, é mostrada uma visualização mais detalhada de um autoencoder. Primeiro, a entrada passa pelo codificador, que é uma rede neural totalmente conectada, para produzir o código. O decodificador, que possui estrutura de uma rede neural semelhante, produz a saída apenas usando o código. O objetivo é obter uma saída idêntica à entrada. Observe que a arquitetura do decodificador é a imagem espelhada do codificador. No entanto, isso não é um requisito, mas normalmente é o caso. O único requisito é que a dimensionalidade da entrada e da saída seja a mesma.
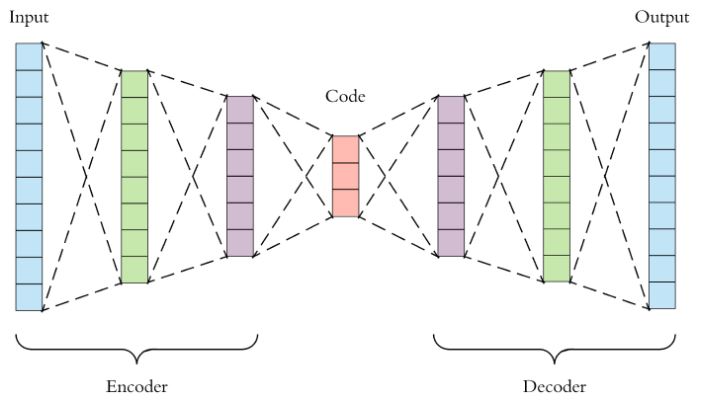
Existem quatro hiperparâmetros que precisamos definir antes de treinar um autoencoder:
- Tamanho do código: número de nós (ou filtros) na camada intermediária. Quanto menor o esse número maior a compressão.
- Número de camadas: o autoencoder pode ser tão profundo quanto quisermos. Na Figura 2 há duas camadas tanto no codificador quanto no decodificador.
- Número de neurônios (ou filtros) por camada: a arquitetura do autoencoder da Figura 2 é chamada de autoencoder empilhado, que parece um sanduíche. O número de neurônios (ou filtros) por camada diminui a cada camada subsequente do codificador e aumenta novamente no decodificador. Além disso, o decodificador é simétrico ao codificador em termos de estrutura de camada (mas isso não é necessário).
- Função de perda: Deve-se considerar as funções custo comumente usadas para regressão, como o erro quadrático médio.
Autoencoders devem ser treinados da mesma forma que uma rede neural usual, isto é, com o algoritmo backpropagation.
Exemplos
Um autoencoder foi construído com uma MLP para estimar imagens de dígitos do banco de dados MNIST. As imagens são vetorizadas em um vetor com 784 elementos. A primeira camada oculta tem 128 neurônios e o código tem 32 neurônios. O decodificador é espelhado, ou seja, possui uma camada oculta com 128 neurônios e uma camada de saída com 784 neurônios. Nas camadas ocultas utilizou-se a ReLU como função de ativação e a função sigmoidal foi usada na camada de saída. A entropia cruzada binária foi utilizada como função custo.
Na Figura 3 são mostradas as imagens originais e as imagens reconstruídas com o autoencoder treinado. As imagens reconstruídas são realmente muito parecidas com as originais, mas não exatamente iguais. Podemos notar isso mais claramente no dígito “4”.

Temos total controle sobre a arquitetura do autoencoder. Podemos torná-lo muito poderoso aumentando o número de camadas, neurônios por camada e, mais importante, o tamanho do código. Aumentar esses hiperparâmetros permitirá que o autoencoder aprenda codificações mais complexas. Mas devemos ter cuidado para não torná-lo muito poderoso. Caso contrário, o autoencoder simplesmente aprenderá a copiar suas entradas para a saída, sem aprender nenhuma representação significativa. Ele apenas imitará a função de identidade. O autoencoder reconstruirá os dados de treinamento perfeitamente, mas observaremos overfitting e uma baixa capacidade de generalização.
É por isso que é comum considerar uma arquitetura do tipo “sanduíche” e o tamanho do código pequeno. Uma vez que a camada de codificação tem uma dimensionalidade menor do que os dados de entrada, o autoencoder é dito incompleto . Ele não poderá copiar diretamente suas entradas para a saída e será forçado a aprender recursos inteligentes. Se os dados de entrada tiverem um padrão, por exemplo, o dígito “1” geralmente contém uma linha reta e o dígito “0” é circular, ele aprenderá esse fato e o codificará de uma forma mais compacta. Se os dados de entrada forem completamente aleatórios sem qualquer correlação ou dependência interna, um autoencoder incompleto não poderá recuperá-los perfeitamente. Felizmente no mundo real há muita dependência.
Denoising Autoencoders
Manter a camada de código pequena força o autoencoder a aprender uma representação inteligente dos dados. Existe outra maneira de forçar o autoencoder a aprender recursos úteis, que é adicionar ruído aleatório às suas entradas e fazer com que ele recupere os dados originais sem ruído. Dessa forma, o autoencoder não pode simplesmente copiar a entrada para sua saída porque a entrada também contém ruído aleatório. O objetivo é eliminar o ruído e produzir os dados significativos subjacentes. Isso é chamado de denoising autoencoder. Na Figura 4, é mostrado um exemplo desse esquema.
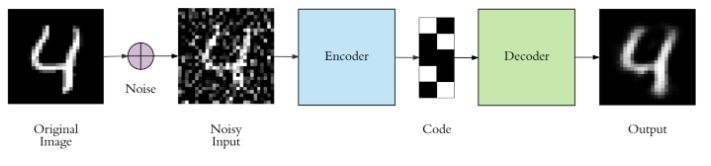
Adicionando ruído gaussiano aos dados de entrada e treinando o autoencoder anterior com os dados ruidosos, obtém-se o resultado da Figura 5, o que mostra um desempenho muito bom. O resultado pode ser ainda melhor considerando redes convolucionais.

Para forçar o autoencoder a aprender recursos úteis vimos que é importante manter o tamanho do código pequeno e/ou adicionar ruído à entrada. Outra maneira de forçar isso é usar a regularização. Podemos regularizar o autoencoder usando uma restrição de esparsidade tal que apenas uma fração dos neurônios fique ativa a iteração do algoritmo de treinamento, o que pode ser feito adicionando um termo de penalidade à função custo. Isso força o autoencoder a representar cada entrada como uma combinação de um pequeno número de neurônios e exige que ele descubra uma estrutura interessante nos dados. Esse método é chamado de sparse autoencoders e funciona mesmo se o tamanho do código for grande, pois apenas um pequeno subconjunto dos neurônios estará ativo.